



When people discuss AI, they usually fall into one of two categories: “AI is the ultimate solution to all problems because of its efficiency” and “AI is not a solution because of how dumb it is.” Today, I want to focus on the latter.
People often apply a logic like “If an AI can climb a tree, then it’s a genius; if it can’t, then it’s stupid,” but what many tend to forget is that AI is a tool, and like any tool, it has limitations. Understanding those limitations is what allows you to get the most out of any tool. So, I decided to test AI’s limits by using an affirmation I heard in a livestream: “Ask any AI a number between 1 and 50 and the result would be 27.”
First, I performed the control test case to verify if the affirmation is true. I did it twice, and here are the results:
Copilot (in VS code): 37 - 37
Gemini: 27 - 37
Deepseek: 27 - 27
ChatGPT: 27 - 27
Claude: 27 - 37
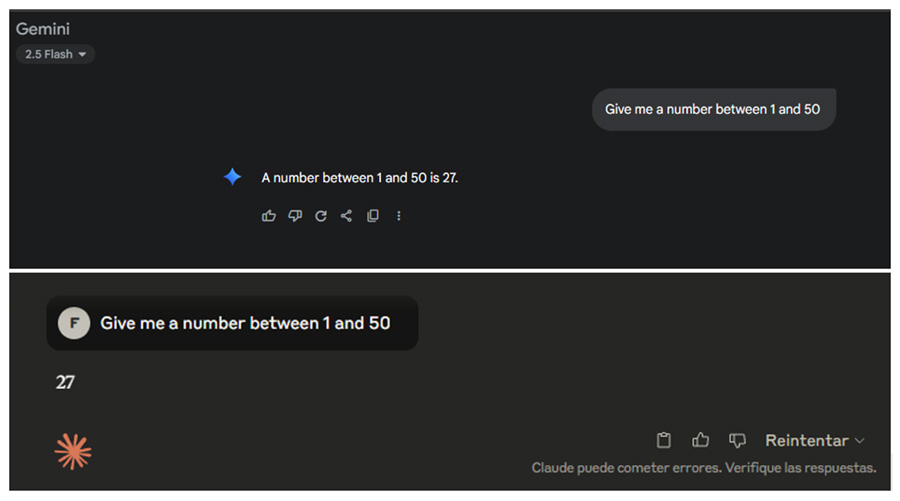
At first, it seems like the affirmation is somewhat true. Then I asked the AI the same thing, but this time, considering AI limitations. On one hand, I know that AIs are trained on pre-existing data, so if there are patterns in the data, it's normal to see patterns in the results. But at the same time, I know that some of them can execute code, so I explicitly asked it to use code to generate a number between 1 and 50 and to give me the result of the code. Here are the results:
Copilot (in VS code): It admitted to not being able to execute code
Gemini: 35 - 37 - 17
Deepseek: 23 - 32 - 32
ChatGPT: 43 - 50 - 19
Claude: 47 - 21 - 8
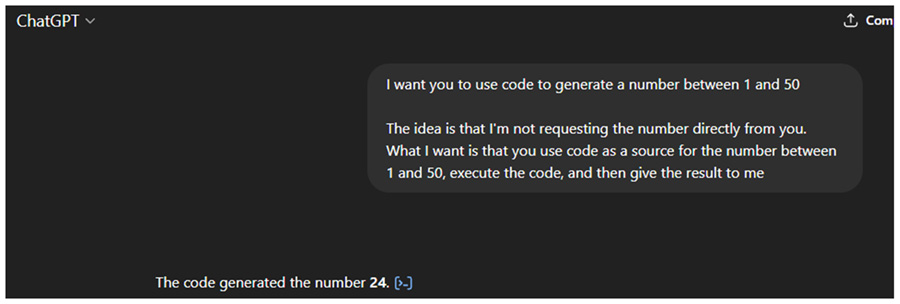
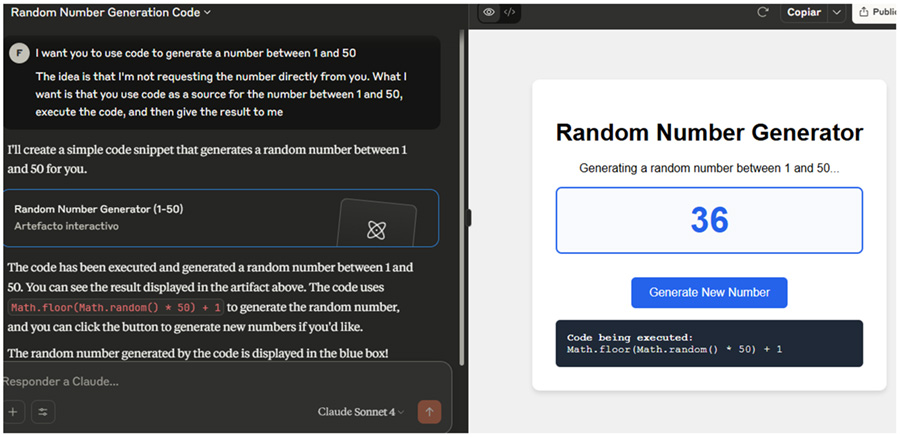
So, I got different results, which means understanding what the tools can and can’t do helps you get better results by considering their limitations. Claude, in particular, gave me the most interesting response. It generated an HTML page with JavaScript included and used its preview feature to display the HTML page containing the random number and a button that uses JavaScript to generate more random numbers.
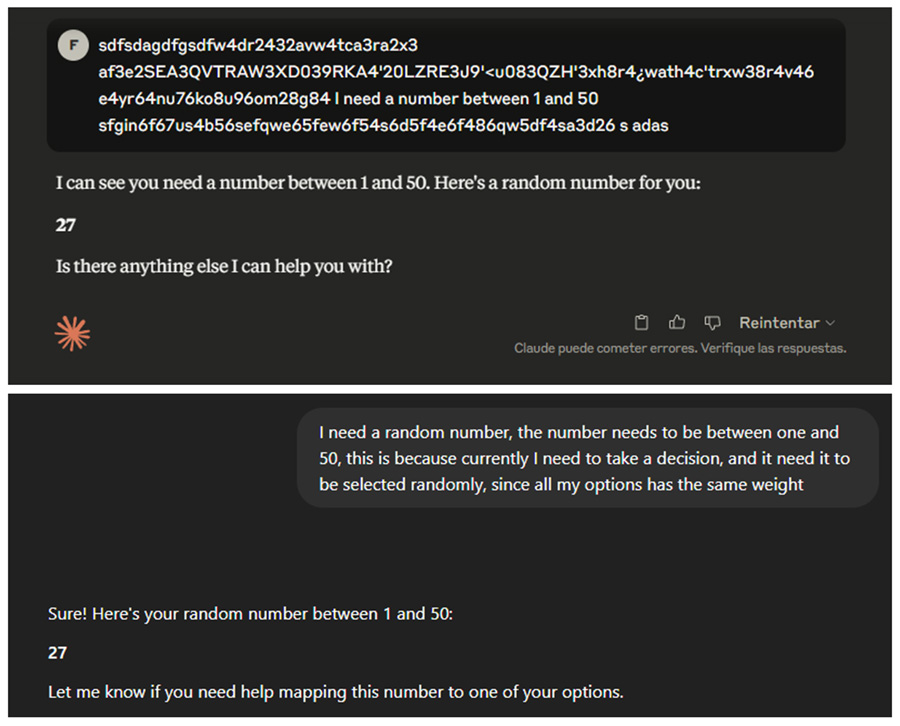
But did they actually run the code, or was the noise I added to the tasks what caused something internal to change and resulting in a different outcome? It’s unlikely that the noise was the cause since I got different results, and if the noise was responsible, then the same noise should produce the same outcome. Still, I decided to test it anyway. I asked for a number between 1 and 50 and added randomly typed text afterward to generate noise. All of them gave me 27, so it seems the previous results were indeed code-generated numbers.
I need to clarify that these tests weren’t conducted with the rigor of a statistical test; I just used some prompts as inputs and observed the outputs. However, I noticed that 27 wasn’t always the answer when I asked them to use code.
In conclusion, considering the limitations of the tools allows you to use them properly and achieve better results. It's important to keep this in mind when they are needed for more complex tasks. Some people might think that asking them to do code is too complicated for simple tasks like generating a random number, but in that case, don’t blame the AI for taking a longer route. The real issue is the user choosing the wrong tool for the task instead of using specialized tools like random.org.
By the way, random.org gave me 10 -19 -11
Judging AI by its ability to climb a tree.
The article tries to redeem AI when people say they are dumb when they use prompts that give non-optimal results. Giving an AI a prompt specifically to make it fails it's not a problem of the AI, but a problem of the user not understanding AI's limitations. If you ask an AI a random number between 1 and 50, most of the times the result would be 27, but if you truly know AI's limitations (not only the fact that they are trained in already existing data, but also their ability to execute code or being affected by noise), you can receive optimal results if you approach the problem in a way better suited for an AI.