



Nowadays, it’s common to see chatbots implemented across all kinds of websites—clothing stores, shipping platforms, restaurants—you name it. These chatbots can be incredibly useful for users (when they work as expected). But that raises an important question: what makes a good chatbot stand out from a bad one?
There are many answers, but most of them revolve around one key idea: how human does it feel? Does the chatbot respond naturally? Does it help you the way a real customer support agent would?
To achieve that level of quality, a chatbot must meet several criteria, such as:
In this blog post, we’ll present a scalable, production-ready solution to fully address that third point—one of the must-haves for any reliable AI chatbot.
Most basic chatbots operate with short-term, in-memory storage and treat each interaction as independent. That might be enough for trivial use cases—but if you want your chatbot to behave consistently, avoid confusing users, and prevent them from abandoning the bot in frustration (or spamming your support team), you need a scalable memory management system.
This introduces several technical challenges:
Our MySQL-based memory store implements the ChatMemoryStore interface from LangChain4j, creating a bridge between the framework's in-memory abstractions and persistent database storage. The architecture consists of three primary layers:
1. Memory Store Layer
The MySQLMemoryStore class serves as the primary interface, implementing LangChain4j's ChatMemoryStore contract. This layer handles the translation between LangChain4j's message objects and our database entities.
2. Service Layer
Service classes (ChatBotMessageService and ChatBotConversationService) provide an abstraction over direct database operations. This separation improves testability and allows for cross-cutting concerns like caching, metrics, and audit logging.
3. Persistence Layer
JPA entities (ChatBotMessage and ChatBotConversation) represent the database schema, with the message entity containing both structured fields and a JSON column for flexible message serialization.

Once we had our architecture set, the next challenge was ensuring the system could handle real-world demands without breaking a sweat. To make our MySQL-backed LangChain4j memory store production-ready, we applied a few essential design patterns.
1. Scaling with Batches and Caching
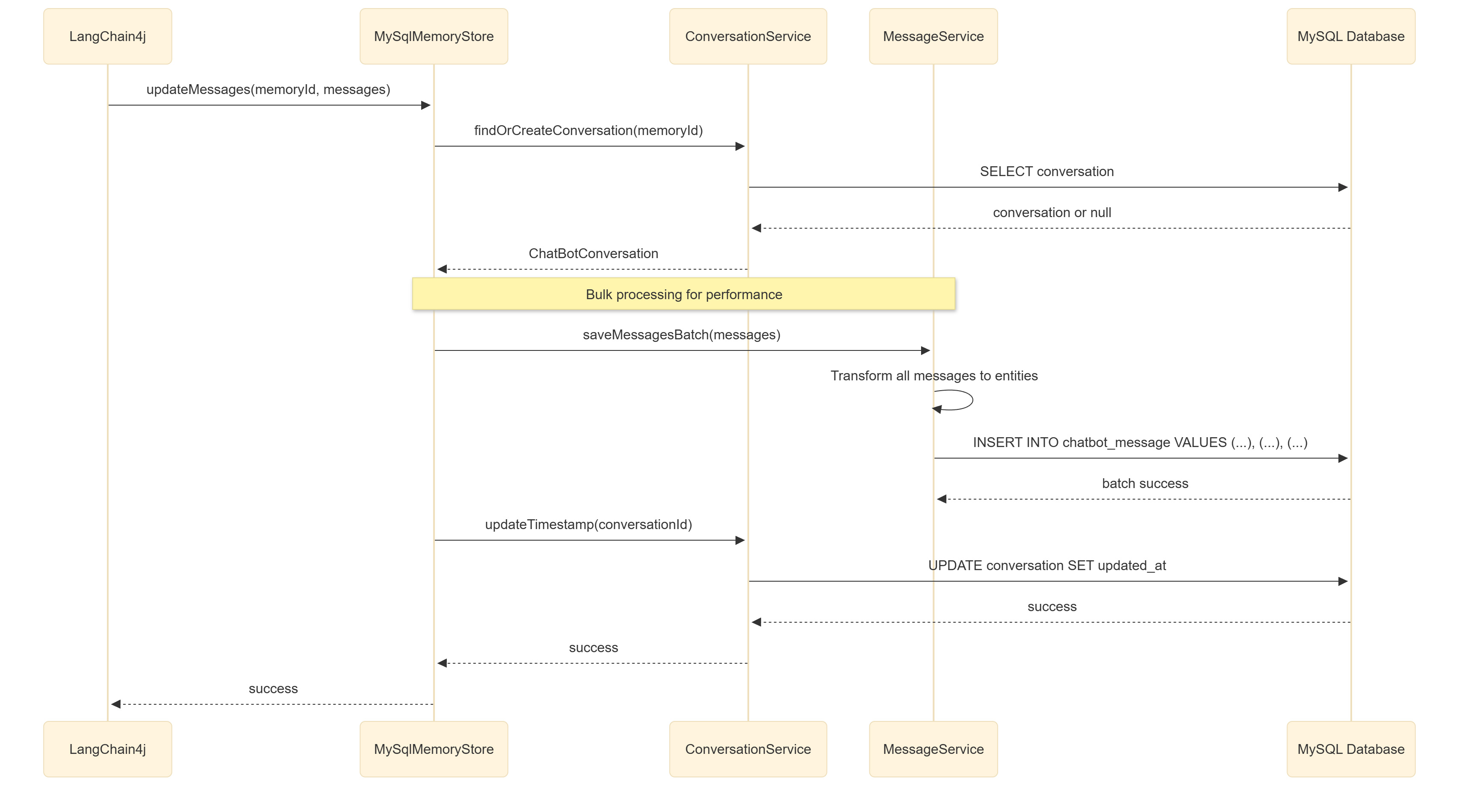
Persisting every single message as it arrives can overload the database and slow down the user experience. To avoid this, we batch multiple messages together and save them in one go. This reduces database calls and keeps our system responsive.
2. Efficient Retrieval at Scale
Chat conversations can get long—sometimes thousands of messages. Loading all of that at once would be slow and costly. Instead, we fetch messages in pages, querying only what’s needed for the current context window.
3. Low-Latency User Experience with Async Writes
Nobody likes waiting. To keep interactions snappy, we decouple database writes from the chat response. When a message arrives, we queue it and return the chatbot’s reply immediately. The message persists in the background asynchronously.
This approach lets users enjoy a smooth conversation without delays caused by database I/O.
Let’s take a closer look at how this memory store works under the hood. While the high-level architecture provides a useful mental model, understanding the actual implementation will give you a clearer idea of how to build, extend, or debug it in your system.
The MySQLMemoryStore class
At the core of our memory system is the MySqlMemoryStore, a class that implements the ChatMemoryStore interface provided by LangChain4j. This is the main entry point that LangChain4j uses to interact with memory—whether it’s appending new messages or retrieving the whole chat history.
The class delegates all low-level logic to service classes, ensuring separation of concerns and clean dependency injection. Each method is responsible for a single operation, such as getMessages, appendMessage, or deleteMemory.
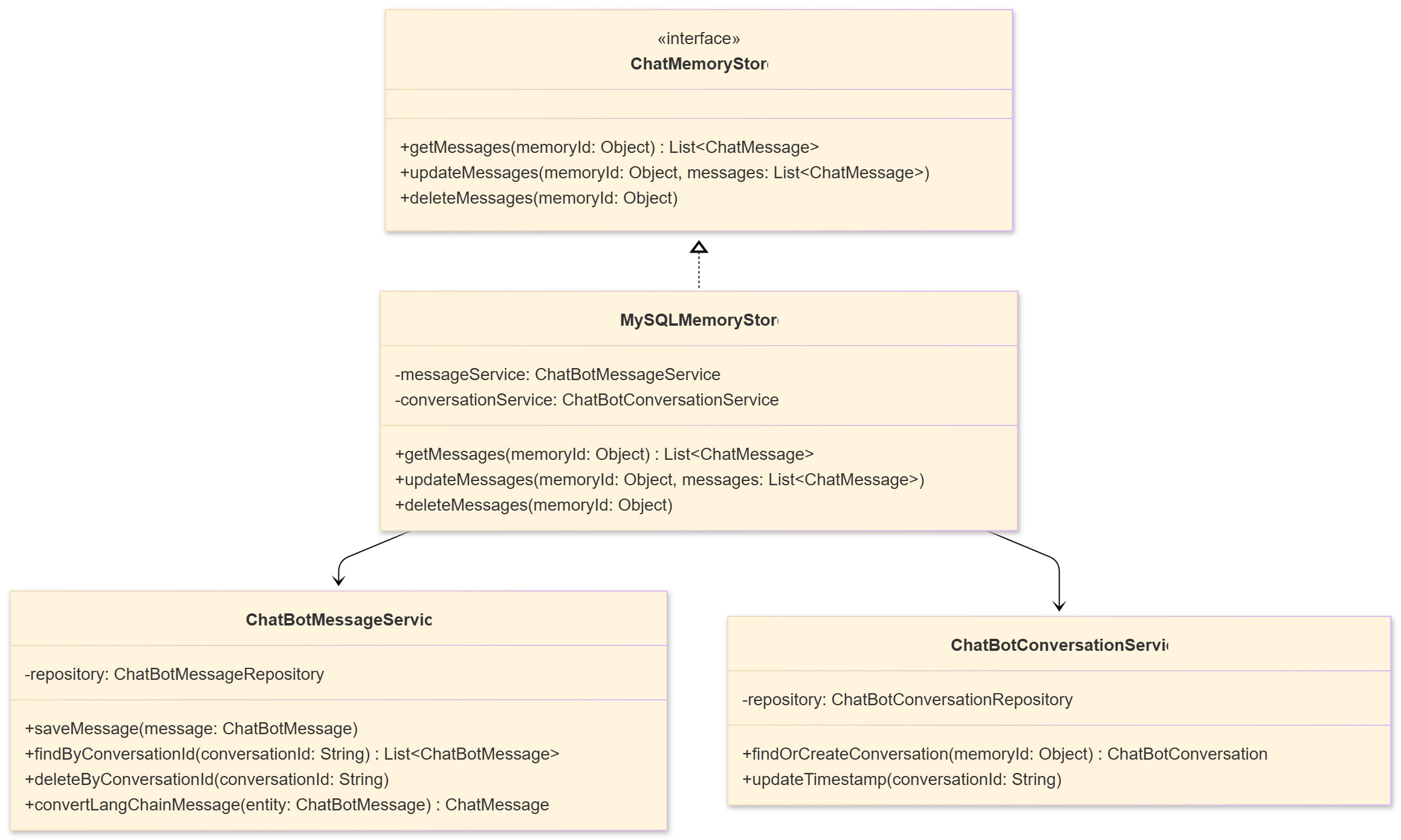
The service classes
Two services handle the core logic:
By encapsulating logic this way, we keep our memory store focused purely on coordinating between LangChain4j and the services.
Entity model and schema design
We use two main JPA entities:
ChatBotConversation: Represents a conversation session. It contains metadata and serves as a parent to messages.
ChatBotMessage: Stores individual messages. Each message includes metadata (message type, created_at) and a JSON field (content) that stores the full LangChain4j message as a serialized blob. This is core to making our schema compatible with LangChain4j; this way, we can use ChatMessage and also add custom metadata to each message row entry.

The JSON column allows us to store arbitrary message content—including future message types introduced by LangChain4j—without needing frequent schema changes. Meanwhile, indexing common fields like conversation_id and created_at ensures fast lookups and retrieval.
This is how an AI chatbot message is composed:
Memory translation and message types
A critical part of this system is converting between LangChain4j’s in-memory message objects (UserMessage, AIMessage, SystemMessage) and our database model. We use a factory-style approach to map between the two, keeping the logic centralized and easy to update as the message model evolves.
Each message is also tagged with a type field (e.g., USER, AI, SYSTEM), which enables fast filtering and more intelligent queries later on.
Closing Thoughts
As we’ve seen throughout this post, managing chatbot memory effectively is not just a backend detail — it’s a fundamental requirement for creating chatbots that feel intelligent, natural, and trustworthy.
It’s easy to start with something simple, like in-memory storage or a quick Redis cache. But as soon as you need persistence, searchability, or reliability across sessions, the complexity ramps up quickly. That’s where having a solid memory layer makes all the difference.
With the approach we’ve outlined, it’s entirely possible to build a scalable, production-grade memory system using tools you likely already know — like MySQL, JPA, and LangChain4j — without over-engineering things from day one.
Let’s keep pushing what’s possible with AI and strong backend fundamentals.